The Sovereign Modular
AI Stack
Kompile projects crawl your data and immediately compile knowledge.
Three pillars. One platform. Models, knowledge, and applications — compiled.
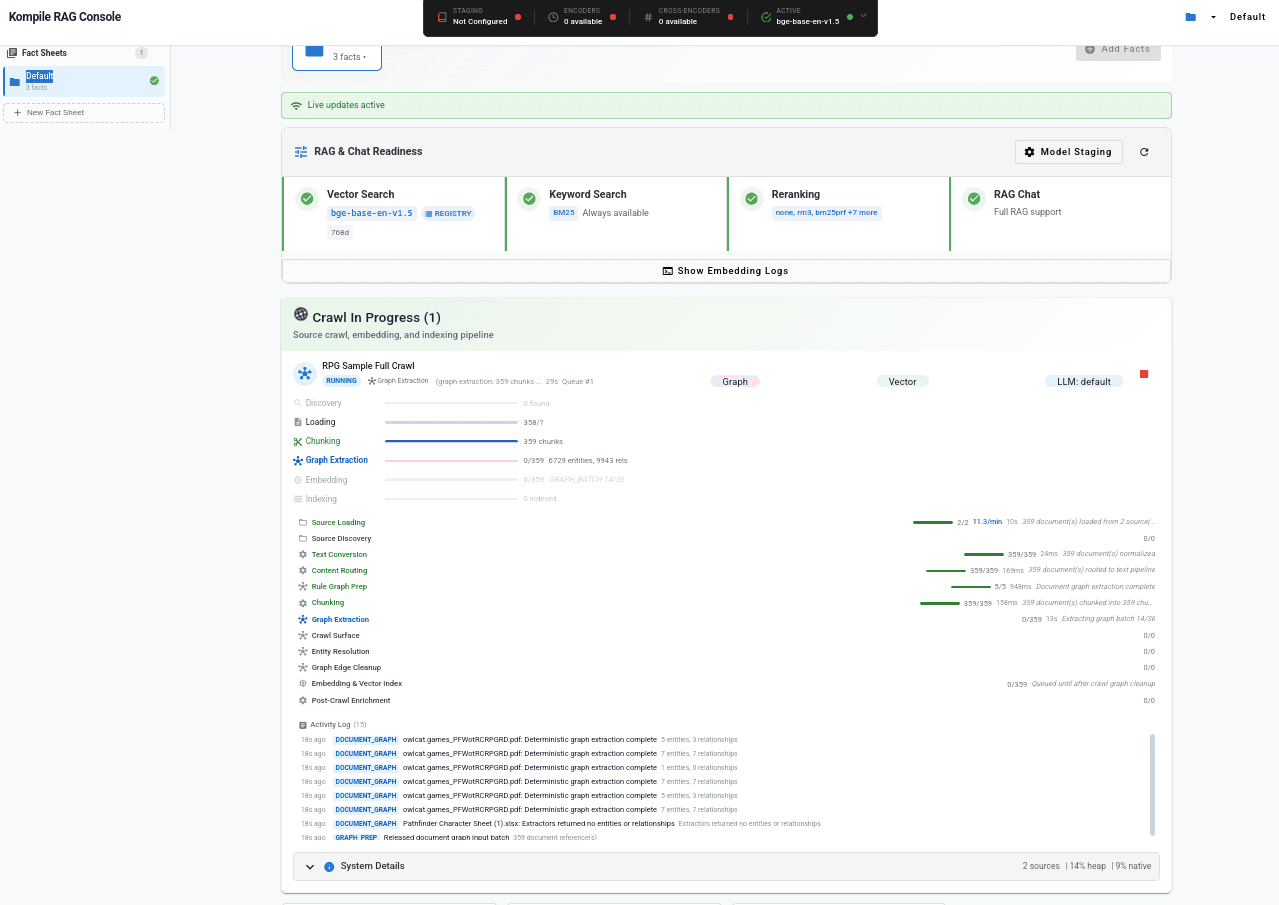
Real-time crawl in the Kompile RAG Console — live pipeline stages, graph extraction, embedding, and activity log
Enterprise AI fails without context. Kompile captures organizational knowledge as graphs and gives every AI system — from agents to copilots — the structured reasoning layer they need to operate in regulated, high-stakes environments.
Three pillars — models, knowledge, and applications — form a sovereign enterprise AI stack you fully own.
THREE PILLARS OF COMPILING
MODELS. KNOWLEDGE. APPLICATIONS.
Compile Models
Reduce costs by running models locally. Download, convert, optimize, and execute models on your own infrastructure — swap providers without changing a line of business logic.
Learn more →Compile Knowledge
Crawl everything — documents, APIs, databases — and compile it into enterprise knowledge graphs with Bayesian reasoning, causal inference, and regulatory-grade audit trails.
Learn more →Compile Applications
One unified modular stack. Build a single interface and CLI harness that works against any provider — no rewrites when you switch.
Learn more →THE STARTING POINT
Kompile Projects
A project is the self-contained unit at the center of everything Kompile does. It crawls your data, compiles it into knowledge, and gives your AI a structured world to reason over.
1. Init
kompile init scaffolds a project with config, directory structure, default pipelines, and model assignments — ready to crawl in seconds.
2. Crawl & Compile
Point the project at your sources — Confluence, Jira, Slack, local files, databases, web — and Kompile automatically crawls, chunks, embeds, and indexes everything into sorted ontologies and knowledge graphs.
3. Act
Chat, query, or build agents against the compiled knowledge. Every project carries its own scoped config, model assignments, vector indexes, and knowledge graph — run multiple projects on the same machine.
kompile init → kompile crawl → kompile chat — from zero to answering questions against your compiled knowledge in three commands.
COMPILE MODELS
Optimize. Train. Deploy. On Your Hardware.
Download models from anywhere, compile them into optimized execution graphs, fine-tune on your proprietary data, and serve them locally — cutting inference costs while keeping full control.
Multi-GPU Automatic Scheduling
Kompile automatically routes workloads across your GPUs. Per-service device routing lets you pin embeddings, LLM inference, and vision models to specific devices, while the resource-aware scheduler handles memory reservation, priority preemption, and admission control.
Device Routing
Route embedding, LLM, VLM encoder, VLM decoder, ingest, and vector population workloads to specific CUDA devices. Auto-route vision models to the largest available GPU.
Dynamic Batching
Continuous batching with per-model priority queues, configurable batch sizes, and max queue delay — maximize throughput without sacrificing latency.
Memory Management
Reservation-based GPU memory pools with admission control, concurrent load limits, and KV cache management with prefix indexing and priority eviction.
RUNS ON YOUR HARDWARE
Graph Optimizations
A 25-pass fixed-point optimizer compiles raw model graphs through iterative simplification, fusion, and hardware targeting. Documented to reduce LLaMA cast operations from 668 to 108.
Cleanup & Simplification
Dead code elimination, constant folding (4 MB limit), identity removal, algebraic identities (add-zero, multiply-one, subtract-self, divide-one), and common subexpression elimination across the full graph.
Attention & Normalization Fusion
Fuse manual Q·K·V attention into dot_product_attention_v2, merge decomposed RMSNorm patterns, and chain RMSNorm→Linear into fused rms_norm_linear ops.
Activation & Horizontal Fusion
Collapse Sigmoid×Mul into SwiGLU, fuse Softmax decompositions, and merge parallel Q/K/V matmuls into a single concatenated weight matmul with strided slicing.
Strength Reduction & Peepholes
Replace pow(x,2) with square, pow(x,0.5) with sqrt, div-by-constant with mul-by-reciprocal. Eliminate idempotent relu/abs, inverse exp/log pairs, and redundant transpose chains.
Memory & Quantization
Rematerialize cheap unary ops to shorten tensor live ranges and reduce peak memory. Auto-quantize large constants to FP16/BF16 (~2× savings) or INT8 (~4× savings) with redundant cast elimination.
Hardware Targeting
CuDNN NCHW→NHWC layout conversion for Tensor Cores, Triton GPU compilation with warp and stage tuning, dynamic kernel selection (fastest, memory, round-robin), and speculative decoding with n-gram speculation.
Training & Fine-Tuning
Customize models on your own data without fragmented external tooling. Every method runs natively inside Kompile.
PEFT / Adapters
LoRA, QLoRA, AdaLoRA, DyLoRA, DoRA, IA3, Prompt Tuning, and Prefix Tuning — with native weight merging when you're ready to ship.
Alignment
DPO, KTO, ORPO, PPO, and GRPO alignment methods with reward model support and streaming training logs.
Distillation
Teacher-student distillation with logit, feature, attention, and combined modes — compress large models into production-sized versions.
Registry & Air-Gapping
A proper model registry with full lifecycle management. Import from HuggingFace, package into .karch archives, and deploy to fully air-gapped environments.
.karch Archives
Self-contained model archives with manifests and SHA-256 checksums. Export, import, publish, and download via CLI or API. Move models across air-gapped boundaries with a single file.
Model Lifecycle
Full promote, replace, convert, and delete workflows. Import from ONNX, TensorFlow, Keras, GGUF/GGML, and SafeTensors formats. Native llama.cpp integration for LLaMA, Mistral, Mixtral, Phi, Qwen, Gemma, Falcon, and more.
IMPORT FROM FRAMEWORKS YOU TRUST
COMPILE KNOWLEDGE
Capture Organizational Knowledge as Graphs
Kompile crawls your data estate and compiles it into enterprise knowledge graphs with multi-entity Bayesian networks, causal inference, entity resolution, and regulatory-grade audit trails — the context layer your AI needs to reason, not just retrieve.
RAG Pipeline
A full retrieval-augmented generation pipeline with pluggable stages. Embed, retrieve, rerank, and generate — each step swappable independently.
Query Transformers
HyDE (hypothetical document embeddings), multi-query generation, query expansion, compression, and step-back prompting — automatically reformulate queries for better retrieval.
Contextual Enrichment
LLM-based chunk enrichment adds surrounding context to each retrieved passage before generation, reducing hallucination and improving answer quality.
Guardrails
Built-in input guards (PII detection, prompt injection, toxicity, topic filtering) and output guards (hallucination detection, relevancy scoring, format enforcement).
Evaluation Harness
Measure RAG quality with built-in evaluators, experiment tracking, eval suites, and dataset management — know when your pipeline is actually improving.
Crawl → Extract → Graph
A single kompile crawl command ingests your data estate through an 8-phase pipeline: load, classify, route, chunk, extract entities via multi-agent LLM + rule-based extractors, resolve duplicates, compute edges, and index vectors — all with adaptive memory-aware parallelism.
20+ Data Sources
Confluence, Jira, Notion, Slack, Discord, Google Workspace, OneDrive, Reddit, Gmail, IMAP/POP3, MBOX, PST, S3, SFTP, SMB, SQL databases, web crawling, and local filesystems.
Content Classification
PDFs auto-classified as text, image-based, or mixed and routed to the appropriate pipeline. Tables, formulas, slides, audio, and email each get specialized extractors.
Multi-Agent Extraction
LLM agents and pattern-based NER agents run in parallel. Cost-balanced batch planning groups chunks by text length to minimize context-window waste. Schema enforcement in None, Lenient, or Strict modes.
Preprocessing Pipeline
Ordered preprocessor chain: language detection, translation, boilerplate removal, Unicode normalization, PII redaction, and content-hash + SimHash deduplication.
Adaptive Parallelism
Memory-aware concurrency with AIMD-style ramp. Collapses parallelism to 1 at 82% heap pressure and ramps back after sustained low pressure. Native memory monitoring via ND4J.
Post-Crawl Enrichment
Automated 4-phase enrichment: clean (dedup, prune, validate, normalize), organize (taxonomy discovery, categorization), process (definition generation), and search index rebuild.
$ kompile crawl start https://docs.example.com \
--depth 3 --graph --graph-schema-mode STRICT \
--chunker tableAwareChunker --watch
Loading... 142 documents from 3 sources
Classifying... 98 text, 31 mixed PDF, 13 spreadsheet
Extracting... 1,847 entities, 2,391 relationships
Resolving... 312 duplicates merged (cosine > 0.88)
Indexing... 4,210 chunks embedded
Done. Graph: 1,535 nodes, 2,391 edgesGraphRAG
Go beyond flat vector search. GraphRAG extracts entities and relationships, builds a structured knowledge graph, and uses graph topology to answer questions that require reasoning across multiple sources — with local, global, and hybrid search modes.
Entity & Relation Extraction
Multi-agent extraction: LLM agents with constrained JSON output, pattern-based NER for PERSON/ORG/LOCATION/DATE, and rule-based email/document graph extractors running in parallel.
Graph Algorithms
Louvain community detection, PageRank, betweenness and degree centrality, Jaccard similarity, BFS/Dijkstra shortest paths, and LLM-generated community summaries for hierarchical reasoning.
Local, Global & Hybrid Search
LOCAL ego-network queries, GLOBAL community-level summaries, or HYBRID with configurable vector weight and hop depth. Three backends: JPA, Neo4j Cypher, or ND4J matrix operations.
Knowledge Graph Architecture
A typed, hierarchical graph model with seven node levels (Source → Document → Snippet → Entity → Table → Attachment → Custom), eleven edge types, and full provenance on every mutation. Multi-tenant isolation via fact sheets and named graph scoping.
Automated Construction
LLM-driven or manual graph building with concept extraction, entity resolution via Levenshtein + embedding cosine + MEBN probabilistic scoring, and graph compaction. Schema presets and enforcement modes keep your ontology clean.
Provenance & Audit Trails
Every node carries source attribution, confidence scores, occurrence/observation/creation timestamps, and TTL expiry. Every edge tracks provenance, similarity score, and bidirectionality. User-pinned nodes resist automated pruning.
Graph Embeddings
Native TransE and RotatE knowledge graph embedding models trained with margin ranking loss and self-adversarial negative sampling. Link prediction, entity similarity, head/tail/relation prediction — all backed by ND4J tensors.
Export & Interop
Nine export formats: CSV, JSON, JSON-LD, GraphML, Cypher dump, HTML with D3.js visualization, SVG diagrams, MediaWiki markup, and Obsidian vault with wikilinks. Merge graphs across environments with fuzzy dedup.
Neo4j & Native Storage
Run against Neo4j with APOC-powered upserts and Cypher queries, or use the built-in JPA + ND4J adjacency matrix graph for embedded deployments. Deterministic entity IDs ensure idempotent writes.
Domain Ontology & Schema
Bring your own domain schemas or let Kompile discover taxonomies via LLM. Enforce type constraints in Strict, Lenient, or None modes. Export discovered taxonomies as reusable schema presets.
Bayesian Networks & Causal Inference
Kompile graphs aren't just structural — they support probabilistic reasoning. Multi-Entity Bayesian Networks (MEBN) ground first-order logic templates against live knowledge graph state, enabling causal inference, event attribution, and probabilistic entity resolution.
Multi-Entity Bayesian Networks
MTheory templates with MFrag fragments: EntityRelevance, CausalInfluence, InformationFlow, and RiskPropagation random variables. CPT strengths derived from KG edge weights and confidence scores.
Situation-Specific Grounding
SSBNGenerator grounds MTheory templates into situation-specific Bayesian networks for a particular query. BFS expansion from seed nodes through the live KG builds the grounded network at query time.
Variable Elimination Inference
Standard variable elimination computes posterior probabilities P(query | evidence) over the grounded network. Conditional probability tables, Noisy-OR gates, and factor operations built on ND4J.
Causal Edge Types
Eight W3C PROV-DM aligned causal relationships: Causes, Enables, Triggers, Contributes To, Prevents, Correlates With, Influences, and Derived From. Temporal chain extraction and counterfactual modeling.
Probabilistic Entity Resolution
MEBN-scored entity resolution computes P(isSameEntity | signals) from name similarity, property overlap, and type compatibility. Works alongside Levenshtein and embedding cosine scoring during graph compaction.
First-Order Logic Predicates
GraphKnowledgeBase evaluates atomic predicates against KG populations. Auto-populated node groups enable universal and existential quantifier evaluation for MEBN constraint checking.
Graph Maintenance & MCP Tools
Graphs are living systems. Kompile provides nine automated maintenance tasks, full mutation audit logging with before/after snapshots, real-time WebSocket change broadcasting, and 30+ MCP tool operations so your AI agents can read, write, traverse, and analyze graphs natively.
9 Maintenance Primitives
TTL sweep (expire stale nodes), orphan cleanup, confidence pruning, component pruning (remove isolated subgraphs), contradiction detection, source/provenance validation, entity re-resolution, stats refresh, and community rebuild — all with pre/post snapshots.
Mutation Audit & Change Tracking
Every node/edge create, update, and delete is captured as a GraphMutationRecord with full before/after JSON snapshots, changeset correlation IDs, trigger source, and actor attribution. Real-time WebSocket broadcasting to connected clients.
MCP Graph Mutation Tools
Create, update, delete nodes and edges. Bulk edge creation. Merge nodes (redirects all edges then deletes). Algorithm cache invalidation on every mutation. Exposed via Spring AI @Tool annotations.
MCP Search & Traversal Tools
Graph search (nodes, edges, metadata), BFS traversal (depth 5), ego networks (radius 3), neighborhood queries, shortest path, hybrid search (local/global/hybrid with vector weight), and visualization data endpoints.
MCP Algorithm Tools
PageRank, degree centrality (in/out/total), betweenness centrality with sampling, Jaccard node similarity, Louvain and WCC community detection, community members listing, and LLM-generated community summaries.
Named Graphs & Labels
Logical sub-graph grouping via named graphs. Label management tools for node tagging. Full multi-tenant isolation with fact sheet scoping on every node, edge, algorithm cache, and maintenance operation.
COMPILE APPLICATIONS
One Interface. Every Provider.
Build one application and one CLI harness against Kompile's unified interface. Swap LLM providers, vector stores, embedding models, and data sources without rewriting a single line of business logic.
LLM Providers
Every provider speaks the same interface. Switch from OpenAI to a local Ollama instance or a self-hosted vLLM server — your application code stays identical. Any OpenAI-compatible endpoint works as a drop-in backend.
API PROVIDERS
CLI AGENT BACKENDS
Embeddings & Vector Stores
The same retrieval code works across all embedding and storage backends. Run fully local with Anserini and SameDiff, or connect to managed services — one API for all.
EMBEDDING MODELS
VECTOR STORES
Data Sources & Crawlers
Crawl your entire data estate through a unified ingest pipeline. Every source feeds into the same chunking, embedding, and indexing stages.
Orchestration & Compute Engines
Go beyond simple chains. Plug in visual workflow engines, business rule systems, or graph databases — all through the same Kompile interface.
Agent-to-Agent Protocol (A2A)
Kompile agents can communicate directly with each other via the A2A protocol, enabling multi-agent architectures where specialized agents coordinate without centralized orchestration.
JOIN THE WAITLIST
Kompile is currently in Early Access Only mode.
Join the waitlist & unlock the full potential of the Modular AI Stack on your own infrastructure.